
 L’Internet des objets se chiffre aujourd’hui en millions d’objets connectés qui génèrent un gigantesque volume de données. Stéphane Allaire, PDG d’Obgenious affirme à l’occasion du SIdO 2018, qu’à horizon 2020 il existera 50 milliards d’objets connectés dans le monde.
L’Internet des objets se chiffre aujourd’hui en millions d’objets connectés qui génèrent un gigantesque volume de données. Stéphane Allaire, PDG d’Obgenious affirme à l’occasion du SIdO 2018, qu’à horizon 2020 il existera 50 milliards d’objets connectés dans le monde.
Une telle quantité de données doit être exploitée de manière réfléchie. Après un état des lieux rapide de l’IoT dans le secteur industriel, nous nous pencherons sur les moyens à mettre en œuvre pour tirer profit de ces données, à la lumière des différents niveaux de traitement adaptés aux spécificités de chaque donnée.
Une réelle prise de conscience des industriels français
Une certitude qui a été confirmée par ce Salon des objets connectés 2018 est que nombre d’industriels ont d’ores et déjà pris le virage de la donnée. Les entreprises sont de plus en plus convaincues que l’IoT est un pilier pour leur développement et quelles doivent franchir le cap.
Le secteur aujourd’hui le plus mature en termes de mise à l’échelle du POC à l’industrialisation est celui de la maintenance. En particulier pour détecter des pannes sur des appareils à distance : Contact roue/rail sur les voies de chemin de fer, poste de transformation électrique… Le projet de poste intelligent développé par Enedis et RTE est un démonstrateur clé pour souligner le potentiel d’une donnée bien exploitée. Il permet d’optimiser les capacités du poste intelligent, pièce maîtresse du réseau de transport d’électricité, par l’apport de technologies numériques et optiques embarquées.
Cependant les industriels ne maitrisent pas encore totalement les objectifs que doivent remplir des projets IoT ni comment exploiter les données produites. Les cas d’usages sont encore trop souvent identifiés après la mise en place du projet IoT, il s’agit de mettre la donnée au service de la performance et non l’inverse. Une des recommandations phares de cette édition du Salon réside dans la valorisation des données produites.
Mettre à profit les données pour en extraire l’information
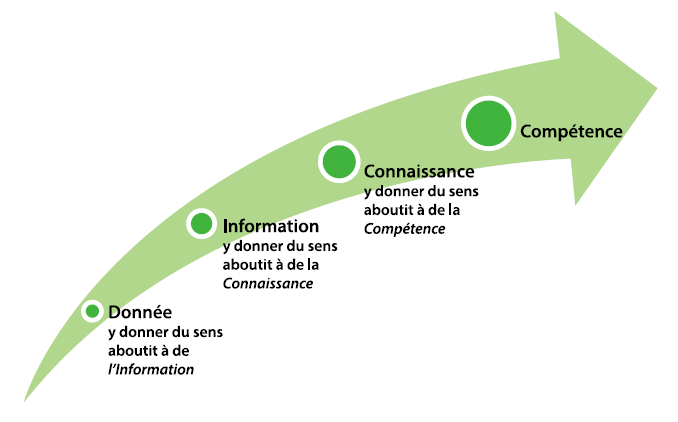
Il s’agit de ne pas perdre de vue le critère numéro 1 du traitement de la donnée qui réside dans la création de valeur. En ce sens, les données reçues par différents capteurs doivent être corrélées pour mener à une donnée directement exploitable. Cette corrélation de données hétérogènes doit s’effectuer à deux niveaux :
- Par une intelligence localisée au plus proche de la production de la donnée : Aujourd’hui, les capteurs sont rendus plus intelligents et autonomes par l’utilisation de nouvelles technologies (qui seront développées dans le 3ème article de cette série). En s’appuyant sur l’exemple du pilotage d’un SmartGrid : les données électriques sont couplées aux données thermiques pour offrir rapidement à l’opérateur une vision claire de l’état du réseau.
- En se basant sur l’expérience métier: il faut définir les objectifs puis déterminer les données nécessaires à l’atteinte de ces objectifs. Il s’agit d’identifier la bonne donnée à exploiter par des raisonnements simples. Dans certains cas, il sera plus opportun pour quantifier la puissance générée par une éolienne de relever la vitesse du vent plutôt que de mesurer l’énergie produite en sortie.
La valorisation des données repose sur des ressources technologiques qui permettent de traiter la donnée de la manière la plus appropriée en fonction de ses spécificités. La sensibilité est une des caractéristiques essentielles de ce traitement.
Trois niveaux de traitement pour trois sensibilités de donnée
Avec la prolifération de la donnée, il devient évident pour toutes les parties prenantes que la sécurité est un point clé de son exploitation.Les technologies de traitement de donnée sont différentiables sur 3 niveaux de localisation :
Le Edge Computing autorise le traitement de la donnée dès le capteur, au plus proche de la production de la data. Cette technologie est à prioriser pour les données qui nécessitent d’être traitées rapidement. Ce procédé requiert des objets connectés intelligents capables de réagir au plus vite sans nécessiter un traitement plus en aval. Le Edge Computing trouve son application directe dans la création de jumeau numérique d’infrastructure. La copie digitale d’une éolienne notamment nécessite d’obtenir rapidement les données du modèle physique pour réagir efficacement et anticiper les maintenances à effectuer.
Le Fog Computing est utilisé lorsque les données sont stockées et traitées dans des infrastructures intermédiaires, à mi-chemin entre l’objet et le cloud. Les données sont alors décentralisées à la périphérie du réseau. La sécurité de ce traitement est dépendante des mesures physiques mise en place pour protéger l’infrastructure. Dans le domaine de l’énergie, par exemple, cette approche favorise un double traitement des données. D’un côté, l’analyse en local donne de la visibilité aux clients sur leur consommation, et de l’autre, elle permet d’adapter la fourniture d’énergie correspondante et de répondre à des objectifs environnementaux.
Le Cloud Computing permet de distribuer les données dans des fermes de serveurs. Ces data centers délocalisés offrent une puissance de calcul et de stockage plus importante que les procédés précédemment cités. Pour beaucoup, la décentralisation de la donnée reste le meilleur rempart contre les cyber-attaques. En ce sens, le Cloud Computing est souvent vu comme la technologie actuellement la plus sûre. Une étude menée par le centre de recherche de Télécom ParisTech en collaboration avec l’Université Tempe dans l’Arizona, propose de d’augmenter la batterie de nos smartphones grâce au Cloud. En déportant les opérations de calcul effectuées par nos terminaux vers des serveurs, la sollicitation de la batterie serait diminuée.
Chacune de ces méthodes de traitement est donc adaptée à une sensibilité de donnée et permet de répondre au mieux à chaque cas d’usage.
Malgré toutes les avancées permises par la récolte et le traitement de la donnée, son acceptation par le grand public demeure une condition sine qua non à l’exploitation de ce potentiel. Il s’agit d’informer et d’expliquer de manière simple les avancées possibles par l’exploitation de la donnée pour que les particuliers soient impliqués de manière favorable dans la valorisation des données.
Sources :
https://blogrecherche.wp.imt.fr/2017/05/29/cloud-computing-smartphones/

